In questi giorni mi sono ritrovato a discutere con i centralinisti del servizio clienti di Tre Italia a proposito di strani redirect che mi succedevano navigando su rete 3 con il mio cellulare. In particolare, succedeva che il mio browser veniva a tutti gli effetti intercettato e rediretto ad un servizio che appartiene al dominio tre.it, el mio caso sdcf.tre.it, che redirigeva a siti pubblicitari.
Ricercando in rete l’indirizzo, ho trovato diverse persone che condividevano il mio stesso problema, così ho deciso di telefonare al servizio clienti per far chiarezza.
La prima telefonata è stata a dir poco futile, nella quale il (non troppo preparato) centralinista mi assicurava che l’indirizzo non aveva assolutamente a che fare con alcun servizio della Tre. La cosa è ovviamente e palesemente falsa, dal momento che è un indirizzo che appartiene al dominio tre.it, registrato dalla società in questione.
A questo punto ho deciso di scrivere sulla pagina facebook di assistenza clienti 3, ottenendo le prime informazioni:
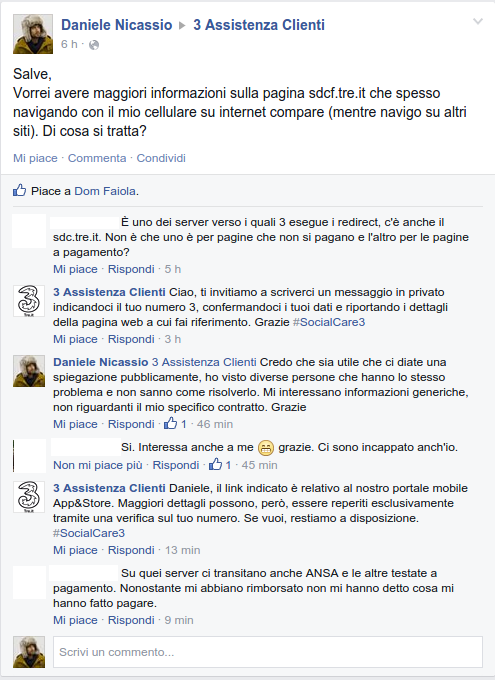
Insistendo col servizio clienti, un’altra operatrice mi cerca di dare maggiori informazioni, ma nemmeno lei sa spiegare qualcosa a proposito di questi strani redirect. L’unica cosa che scopro è che sul mio conto sono stati addebitati 14 centesimi per visualizzazione di contenuti di “editoria mobile”, che sono riconducibili a testate giornalistiche che hanno stretto contratti con Tre Italia per addebitare automaticamente sul conto dei visitatori che accettassero di visualizzare le pagine con i loro articoli. L’operatrice mi assicura che quando queste pagine si presentano, da qualche parte deve essere specificato che il contenuto è a pagamento, e io di questo sono sicuro. Ma sono anche relativamente certo che non avrei mai accettato di pagare 7 o 9 centesimi per visualizzazione se ne fossi stato cosciente. Sento puzza di soldi facili per le testate giornalistiche e Tre.
Detto questo, chiedo che Tre non accetti mai in futuro addebiti sul mio conto che non siano relativi all’utenza telefonica, come ad esempio questi addebiti da siti quali corriere.it o repubblica.it. L’operatrice insiste che questo non è possibile, farfugliando qualcosa a proposito del fatto che Internet è libera. Devo dire che se anche Internet fosse libera, cosa di cui dubito sempre di più, Tre si sta impegnando in tutti i modi per evitare che sia così.
Finito questo piccolo sfogo, che racconta la mia esperienza con gli addebiti Tre, veniamo alla parte tecnica, che più si addice a questo blog. Ho provato a realizzare un’applicazione Android che, senza necessità dei permessi di root sul telefono, sia in grado di intercettare le chiamate ai servizi di tre.it riconducibili a pubblicità o addebiti indesiderati. Cercando in rete ho scoperto degli indirizzi sono usati da Tre per “servizi” che hanno (a mio avviso) come scopo principale quello di addebitare costi a utenti inconsci, e che si possono trovare preinseriti addirittura nei browser predefiniti dei telefoni brandizzati Tre. Tutto questo è un insulto alla clientela, se non si può già paralare di truffa.
L’applicazione che ho sviluppato serve ad intercettare eventuali redirect indesiderati del browser verso questi indirizzi:
sdc.tre.it
sdcf.tre.it
mobile.tre.it
portal.tre.it
L’applicazione è per ora in fase di test, potrebbe non funzionare bene e non in tutti gli scenari, ma è già qualcosa. L’ho già rilasciata sperando che possa funzionare almeno in parte per chi condivide questi problemi, soprattutto perchè anche cercando in rete, o chiamando il servizio clienti sembra che questi problemi non si possano risolvere altrimenti.
Ecco il link all’applicazione nel Google Play Store:
https://play.google.com/store/apps/details?id=it.nicassio.addebititreblocker
Update:
Aggiungo un link ad un relativo articolo di bastabollette.it che suggerisce anche un approccio legale al problema: https://bastabollette.it/telefonia/h3g/sdcf-tre-come-difendersi/